Following the collection of data through a survey or other research method, data must be cleaned. The data cleaning process, also known as data scrubbing or data cleansing, can have a huge impact on the reliability and validity of your final data, as it ensures that you are only using the highest-quality data to perform your analysis. By rushing or eliminating the data cleaning step, you run the risk of including false, misleading, or duplicated records in your final dataset. Following a thorough data cleaning process will minimize errors made due to data that is formatted incorrectly.
Steps to Clean Data
The steps to clean a dataset may vary slightly depending on the research methodology, and if the resulting data is largely quantitative or qualitative. However, the below represent some of the most commonly used steps in the data cleaning process.
1. Remove Duplicate and Incomplete Cases:
Datasets may sometimes include duplicate cases if a respondent accidentally took a survey twice, data were combined from multiple sources, or there was an error when retrieving the dataset. Depending on the data collection tool you use, it is also possible that an initial dataset includes incomplete cases, for example, if a survey respondent took only half of the questions. The first step in data cleaning is to remove any duplicate or incomplete cases so that you are examining a set of unique and complete cases.
2. Remove Oversample:
In many cases, particularly when conducting survey research, a researcher may collect more responses than they need. For example, you may be aiming to gather 500 completed survey responses, of which 250 identify as female and 250 identify as male, but end up gathering 700 completed responses, 300 who are female and 400 who are male. As you have 50 extra female completes and 150 additional male completes, you will need to cut back the data so that the sample is equally representative of male and female respondents. Researchers should use a randomized method to remove any oversample in order to meet the sample requirements so that each respondent has an equal chance of being included or excluded in the final dataset.
3. Ensure Answers are Formatted Correctly:
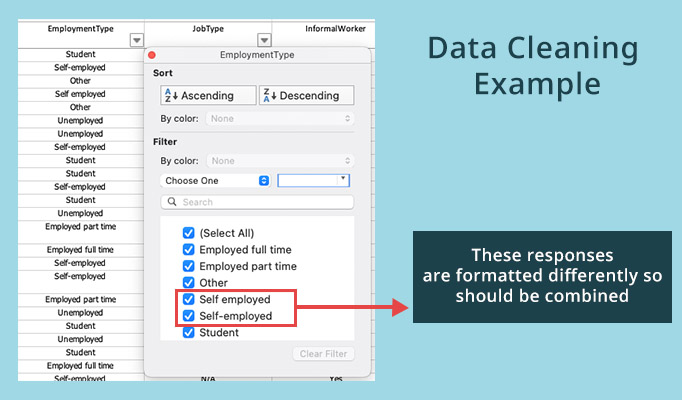 Raw data may come in several different formats when it is first accessed – for example, a multiple-choice survey question about ice cream flavors may list answers as numbers 1, 2, and 3 when in the question they represented text choices Vanilla, Chocolate, and Strawberry. Depending on how the data will be analyzed, researchers may want to replace the numerical data with the textual data. If data is being combined from multiple surveys or data sources, there could be two different words used to represent the same thing – for example ‘Not sure’ vs ‘Unsure’. To avoid these cases being represented as unique answers, they should be combined.
Raw data may come in several different formats when it is first accessed – for example, a multiple-choice survey question about ice cream flavors may list answers as numbers 1, 2, and 3 when in the question they represented text choices Vanilla, Chocolate, and Strawberry. Depending on how the data will be analyzed, researchers may want to replace the numerical data with the textual data. If data is being combined from multiple surveys or data sources, there could be two different words used to represent the same thing – for example ‘Not sure’ vs ‘Unsure’. To avoid these cases being represented as unique answers, they should be combined.
4. Remove Nonsense Answers and Unreadable Data:
Datasets may include nonsense answers, such as those including symbols or other words or numbers which do not make sense in the context of the question or field. It is also possible when importing data from multiple files that some data may be unreadable. These cases should be removed from the final dataset.
5. Identify and Review Outliers:
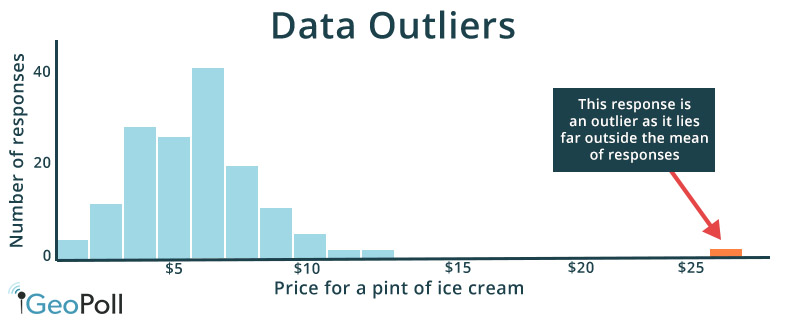
Outliers are data points that lie outside the majority of responses and should be carefully reviewed and validated before being included in the final dataset. While some outliers may be valid, such as one respondent stating they have 10 siblings when the majority of respondents have 2 or 3 siblings, others may demonstrate that the respondent did not understand a question or is falsifying responses, such as an answer which indicates a respondent would pay $1000 for a pint of ice cream. Outliers that seem out of the reasonable realm of possibility should be removed from a dataset as they will skew key calculations.
Step 6. Code Open Ended Data
The coding of open-ended response data is an entire process unto itself, however, it is also an important part of data cleaning. Datasets that include open-ended data can be particularly time-consuming to clean as data can be lengthy, unrelated to the question at hand, or hard to decipher. In order to glean statistical insights from qualitative responses, open-ended responses may be coded into categories, a process that involves first reviewing all responses manually to create categories, and then going through open-ended data and actually placing it into the categories. If the dataset is in multiple languages, this step may also include translating responses into the language the analysis will be conducted in.
7. Check Data Consistency:
Check on logic relations and ensure there are correlated data sets, and there are no inconsistencies including contradictions and gaps in data. In case of any inconsistencies between the data and the questionnaire, the issues should be flagged in order for you to decide a way forward or if data should be excluded from the final dataset.
8. Perform Final Quality Assurance Checks:
After you have gone through the above steps, researchers will still want to perform manual quality assurance checks of the data before starting data analysis. This final step should examine the dataset in its entirety, looking to see if there are anomalies in data for any individual question or data point and double-checking that data is formatted correctly.
Cleaning Survey Data
Some of the above steps can be performed by data cleaning tools including SAS and R software, however manual oversight is required to ensure no errors or inconsistencies in a dataset are missed. GeoPoll prides itself on delivering high-quality and accurate data from our mobile-based surveys and other research methods. Our research team performs data cleaning and coding on each of our datasets before they are delivered to clients. To learn more or contact a member of our team, please contact us.